Transformer Model [트랜스포머 모델] 정리 - [1]
이 글은 Transformer 에 대해 직관적으로 이해하고 이해한 바를 잊지 않기 위해 여러 글을 참고하여 작성 / 정리해둔 글입니다.
1. Transformer 배경
기존 seq2seq 모델의 한계 [입력 시퀀스를 벡터로 압축하는 과정에서 정보 일부 손실 등] 를 보정하기 위해 attention 이 나왔다. 그렇다면 attention을 보정하기 위해서 추가로 사용하는 용도가 아니라 attention 만으로 인코더와 디코더를 만들어본다면?

2. Transformer 란?
트랜스포머 모델은 문장 속 단어와 같은 순차 데이터 내의 관계를 추적해 맥락과 의미를 학습하는 신경망이다.

트랜스포머는 RNN을 사용하지 않지만 인코더-디코더 구조를 유지하고 있다. 이전 seq2seq 구조에서는 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점[time step]을 가지는 구조였다면 이번에는 인코더와 디코더 단위가 N개로 구성되는 구조이다.

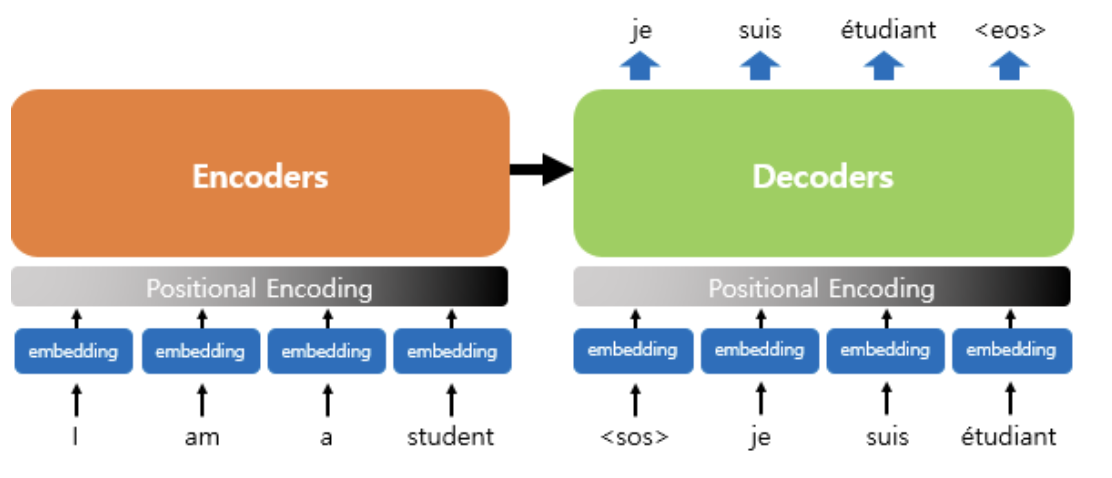
트랜스포머를 제안한 논문에서는 인코더와 디코더의 개수를 각각 6개 사용했다. 위의 그림이 인코더와 디코더 각 6개씩 존재하는 트랜스포머의 구조를 보여준다.

위의 그림은 트랜스포머 구조이다. 디코더의 경우 seq2seq 구조와 같이 시작 토큰 <sos>를 입력받아 종료 토큰 <eos> 이 나올 때까지 연산을 진행한다. 다른 점은 트랜스포머의 인코더와 디코더는 단순히 각 단어의 임베딩 벡터들을 입력받는 것이 아니라 임베딩 벡터에서 조정된 값을 입력받는다.

트랜스포머의 전체 아키텍처 그림이다.
3. 포지셔널 인코딩 [Positional Encoding]

RNN이 자연어 처리에서 유용한 이유는 단어를 순차적으로 입력받아 처리하는 특성으로 인해 각 단어의 위치 정보 [position information] 를 가질 수 있기 때문이었다.
<-> 하지만 트랜스포머의 경우 순차적으로 입력을 받는 방식이 아니기 때문에 단어의 위치 정보를 다른 방식으로 알려줘야 한다.
트랜스포머는 단어의 위치 정보를 얻기 위해 각 단어의 임베딩 벡터 위치 정보들을 더하여 모델의 입력으로 사용하는데, 이를 포지셔널 인코딩이라고 한다.
그림으로 나타내면 아래와 같다.

트랜스포머는 위치 정보 값을 만들기 위해 두 개의 함수를 사용한다.

사인 / 코사인 함수의 그래프를 생각해보면 요동치는 값의 형태가 떠오르는데, 트랜스포머는 사인 함수와 코사인 함수의 값을 임베딩 벡터에 더해줌으로 단어의 순서 정보를 더해준다. 위의 식을 이해하기 위해서는 임베딩 벡터와 포지셔널 인코딩의 덧셈은 사실 임베딩 벡터가 모여 만들어진 문장 행렬과 포지셔널 인코딩 행렬의 덧셈 연산을 통해 이루어진다는 것을 이해해야 한다.

$pos$ 는 입력 문장에서의 임베딩 벡터의 위치를 나타내며, $i$ 는 임베딩 벡터 내의 차원의 인덱스를 의미한다. 임베딩 벡터 내의 각 차원의 인덱스가 짝수[$pos, 2i$]인 경우에는 사인 함수의 값을 사용하고, 홀수[$pos, 2i+1$]인 경우에는 코사인 함수의 값을 사용한다. 또, $d_{model}$ 은 트랜스포머의 모든 층의 출력 차원을 의미하는 트랜스포머의 하이퍼파라미터 이다.
각 임베딩 벡터에 포지셔널 인코딩의 값을 더하면 같은 단어여도 문장내의 위치에 따라 입력으로 들어가는 임베딩 벡터의 값이 달라지기 때문에 순서 정보가 보존된다.
포지셔널 인코딩은 이후 연구에서 특정 상황이나 데이터 유형에 더 적합하도록 다양하게 변형되어 제안되었다.
1) 학습 가능한 포지셔널 인코딩 [Learnable Positional Encoding] : 포지셔널 인코딩 값을 모델 학습 과정에서 함께 학습하도록 설계한다. 이를 통해 모델이 데이터에 특화된 위치 정보를 스스로 학습할 수 있게 된다.
2) 상대적 포지셔널 인코딩 [Relative Positional Encoding] : 단어 간의 절대적 위치 대신 상대적 위치 정보를 사용하는 방식이다. 이는 특히 긴 시퀀스를 다룰 때 효과적일 수 있으며, 문맥에 따라 단어 사이의 관계를 더 유연하게 모델링 할 수 있게 한다.
4. 어텐션 [Attention]
트랜스포머에서 사용되는 세 가지의 어텐션은 다음과 같다.

Encoder Self-Attention 은 Attention이 인코더에서 이루어지지만, Masked Decoder Self-Attention 과 Encoder-Decoder Attention은 디코더에서 이루어진다. Self-Attention 은 Query, Key, Value 가 동일한 경우를 말한다. Encoder-Decoder Attention 에서는 Query가 디코더의 벡터인 반면 Key와 Value가 인코더의 벡터이므로 셀프 어텐션이라고 하지 않는다.
* 이 때, Query, Key, Value 가 같다는 것은 벡터의 값이 같다는 것이 아니라 벡터의 출처가 같다는 의미이다.
Encoder Self-Attention : Query = Key = Value
Masked Decoder Self-Attention : Query = Key = Value
Encoder-Decoder Attention : Query : Decoder Vector / Key = Value : Encoder Vector

트랜스포머의 아키텍처에서 위의 세가지 어텐션이 어디에서 이루어지는지 보여주는 그림이다. 각 어텐션에 'Multi-head' 이름이 붙어 있다. 이는 트랜스포머가 어텐션을 병렬적으로 수행하는 방법을 말한다.
5. 참고
16-01 트랜스포머(Transformer)
* 이번 챕터는 앞서 설명한 어텐션 메커니즘 챕터에 대한 사전 이해가 필요합니다. 트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 Attention i…
wikidocs.net
트랜스포머 모델이란 무엇인가? (1) | NVIDIA Blog
AI 분야의 혁신에 함께하고 싶다면 트랜스포머(transformer)에 주목하세요.
blogs.nvidia.co.kr
Transformer의 큰 그림 이해: 기술적 복잡함 없이 핵심 아이디어 파악하기
트랜스포머의 핵심 아이디어를 이해하세요. 코딩 및 복잡한 이론 없이, 트랜스포머의 핵심만 이해하시고 바로 응용하세요.
medium.com